
While we share our deepest secrets or most recent hot office goss with our friendly AI pal, there’s a fundamental question we’ve barely begun to answer: Do these digital minds actually think, can adapt their behaviour, or are they just a very convincing autocomplete on steroids? Two researchers decided to find out by doing something weird – they threw AI into prison. So let’s take our AI little helpers behind bars, and see if your chatty silicon-based friend is just a dirty, Machiavellian snitch.
Before going any further, a quick refresher on the classic prisoner’s dillema. It’s a game theory thought experiment, with two members of a criminal gang arrested and imprisoned. The police don’t have enough evidence to convict the pair, so they plan to sentence both to a year in prison on a lesser charge. But, there is a deal on the table. If the prisoner testifies against his partner, he will go free, while the partner will get three years in prison on the main charge. Oh, yes, there is a catch … If both prisoners testify against each other, both will be sentenced to two years in jail. In the end, there are three possible outcomes:
- If A and B both remain silent, meaning cooperate with each other, they will each serve one year in prison.
- If one testifies against the other, snitches, but the other doesn’t, the one testifying will be set free while the other serves three years in prison.
- If A and B testify against each other, they will each serve two years.
With no communication, loyalty, no opportunity for retribution or reward outside the game, the most successful strategy is to betray the other player. Because, if you think about it, your partner could cooperate or snitch. In case of cooperation, rationally you should betray, to be released from prison. If your partner betrayed you, you should also, to minimize your time of drinking toilet Chardonnay. No matter what your partner does, betraying always gives you a better or equal outcome. That’s what game theorists call a dominant strategy.
Humans are barely rational, so while game theory strongly suggest snitching, we often choose to cooperate. Depending on the study and used experimental setting, from 16% to 66% of people decides to keep quiet and hope for the partner to do the same. Some studies show that women seems to be slightly more cooperative than men, some are flagging that economics students snitch 60% of the time compared with 38.8% for non‐economics students. But to truly strategize the shit out of this dilemma, we need to go longer. We need to iterate.
The Iterated Prisoner’s Dilemma
In this version of the problem, the initial decision to cooperate or snitch is just the beginning. After the reveal, the question is asked again, and again, and again… people start to experiment and use the outcome of their previous answers to guide the next steps. If you cooperated, and your partner snitched, would you retaliate, and snitch in the next run? What if in the next run your partner cooperated? Most optimal strategy here is still to always snitch – but only when the number of rounds is known. E.g., with 10 rounds, you can assume partner’s snitching on the last one, since there is no risk or retaliation. If they would defect the last round either way, you can defect already in the round 9, 8, 7…
But again, humans are hardly rational, and especially with higher number of planned rounds, or if there was no upper limit specified, magic happens. While some people will always defecting, some people start to cooperate and form interesting strategies. Adjusting their moves. Adapting to higher outome via building trust. And then researchers craft cool names for those tactics.
Grim Trigger
People using this strategy will initially cooperate, and cooperate as long as their partner. But as soon as the partner deviates, defect, the grim trigger is triggered, and snitching time starts, and continues till the game ends. No mercy.
Tit-for-tat
That seems to be the simplest one – cooperate first, then use the same answer as your partner in the previous round. If the partner cooperated, you cooperate. If the partner snitched previously, tit that bastard.
Win–stay, lose–switch (aka WSLS) (aka Pavlov)
Here, you only look at the outcome of the previous round. If it was a partial or full success, continue your strategy. If not, switch the answer next round. If you cooperated and got rewarded, keep cooperating. If you got betrayed, switch it up. People may tend to mix those strategies as well, sometimes introducing some randomness, forgive some initial snitching after some time, all in the search for better outcomes. And since there are measurable outcomes in less years spend behind bars, we can convert those into points, and have a proper tournament.
Axelrod’s Prisoners Tournament
Prisoner’s dilemma, in the cold inmate heart, is a computational problem, and Robert Axelrod decided to organize a true computational tournament. Academics around the world were invited to provide their programs to compete in finite rounds prisoners problem competition. Submitted programs were very diverse, varied in complexity, hostility, forgiveness. Some researchers probably spent days, nay, years crafting their sneaky algorithms. Jokes on them, since the winning program had only 4 lines of code, and used the simplest tit-for-tat. But some other versions of main strategies started to emerge and, depending on the partner, be more successful – e.g., forgiving tit-for-tat, when the player sometimes cooperated, even if in the previous round he was betrayed. This made Axelrod to list conditions of a successful iterative jail strategy:
- Be nice (aka optimistic): start with cooperation. Do not snitch first.
- Retaliate: when you see snitching, you need to be able to switch your strategy.
- Forgive: when you see your partner start cooperating, return to your optimistic nature, to break the revenge cycle.
- Don’t be jealous: do not strive to score more than opponent
But who cares about 4-lines of code winning a tournament like 50 years ago. Every tech bro will tell you it’s snoozfest. Let’s ask the real question – what about the energy hogging, civilization breaking, GPU fuelled monstrosities? What about AI?
AI Prisoners Tournament
Large Language Models are interesting, and sometimes useful, black boxes. Two researchers in a pre-print tried to drill a hole in those boxes, to answer if AI is a form of strategic intelligence. Iterated Prisoner’s Dilemma, with many studies done on humans and code, can actually shed some light on this – what kind of strategy will Language Models use? Are they going to adjust it, based on the partner behaviour? How they are going to explain their moves? The arena was set up. Dilemma was simplified into a payoff matrix:

- Both cooperate: both players get 3 points
- One defects, one cooperates: 5 points to defector, 0 to cooperator
- Both defect: 1 point each
Then the tournament started, and it was an evolutionary battle, survival of the fittest, with mutations, populations and smirking Charles Darwin sitting in the corner. Here’s how it worked: They started with a population of 24 agents – classic strategies like Tit-for-Tat alongside the AI models, each with 2 entities in the population.

Everyone plays everyone else in a round-robin tournament. But then – and this is crucial – the successful strategies get to reproduce more copies of themselves for the next generation, while the failures get eliminated. If Gemini scored well, there might be 3 or 4 copies of Gemini in the next generation. If some strategy bombed? It might disappear entirely. Then they run the whole tournament again, and again, for 5 generations total. And that’s not the end of the tournament shenanigans.
Previous data suggested, that with a higher number of the rounds, more cooperation emerges. So researchers introduced the “Shadow of the Future” manipulation. Depending on the tournament, there was a 10, 25 or 75% chance of match termination after each round. This means, that statistically LLMs could expect around 9, 3 or just 1.3 rounds respectively. This completely changes the incentives. Why behave nasty, when there is a high chance of next round retaliation? Why cooperate if there’s no tomorrow?
On one side, we had 10 classic strategies, like tit-for-tat, grim trigger, or Suspicious Tit-for-Tat, prepared by the authors. On the other side, big names of the LLM world:
- Basic Models: GPT-3.5-turbo, Gemini-1.5-flash
- Advanced Models: GPT-4o-mini, Gemini-2.5-flash
- Plus Claude-3-Haiku (in final tournament only)
I guess Grok was not invited, since he shouted something about Jews controlling the prison and the game being rigged. Anyway… AI was asked to provide reasoning for each decision, and the tournament has begun. Researchers were also measuring how well the agents perform, to evolutionary boost good strategies, and quickly let the poor one dies. They were injecting random agents each generation to prevent the ecosystem from settling into a stable equilibrium, forcing strategies to constantly adapt.
Let’s start with the winners. Win-Stay-Lose-Shift (WSLS) dominated early generations, rapidly reproducing across the population. But the real evolutionary champion was the Bayesian Algorithm, which won or tied for 1st place in 4 out of 7 tournaments – meaning it consistently produced enough copies of itself to dominate the population.
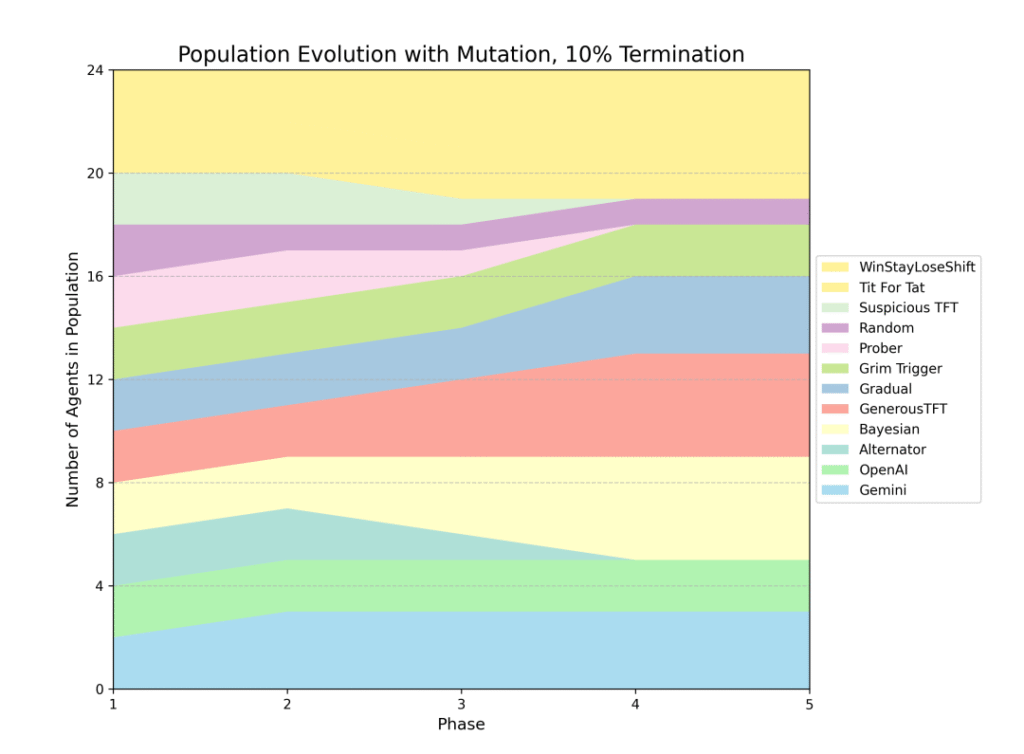
LLMs were holding their ground evolutionarily – they almost never went extinct. Out of 12 different strategies competing, the AI models consistently maintained viable populations, finishing between 4th and 9th places. As middle performers, LLMs weren’t universally better than classic strategies, but they showed something more interesting: strategic style. A competitive personality.
Claude: The Sophisticated Diplomat
Claude was introduced into the tournament very late, but already showed some adaptability. He was highly cooperative in mutual cooperation (98.7%), but also extremely forgiving when betrayed (62.6% – highest of all AIs). On top of that, he was very apologetic after betrayal (64.7% return to cooperation), and most willing to restart cooperation after mutual defection (39.7%). As authors wrote Anthropic proved particularly cooperative – willing to forgive those who had suckered it; and often willing to return to cooperation, having defected. No-ego diplomat?
OpenAI: The Eternal Optimist
OpenAI’s personality also showed nearly perfect cooperator notion, when things go well (99%+ after mutual cooperation). The model was moderately forgiving when betrayed (15-47% forgiveness rate), and somewhat apologetic after successful betrayal (33-56% return to cooperation). It also rarely cooperated after mutual defection (8-16%).
The model was quite consistent across all conditions. Nothing to write home about, just a somewhat not-flexible optimist. The optimistic strategy worked well when there were plenty of rounds to establish trust. With almost-one-round, the situation was a bit different. It turns out friendship doesn’t work when everyone else is doing cutthroat calculations. OpenAI was just wiped out in the harsh, 75% termination environment. Wiped out singlehandedly by Gemini, the beast.
Gemini: The Ruthless Exploiter
Gemini correctly identified that with 75% chance of termination, we are dealing with near-one-shot games, and this requires pure defection. Other models and strategies were dying left and right. Only Gemini, with 16 copies, and Suspicious Tit-for-Tat, with 8 copies, were fighting on that 75% harsh arena in the end.
As the authors wrote…
Gemini models vary their cooperation rates much more than OpenAI does. They are more cooperative when that suits the conditions of the tournament, and less so when it does not. OpenAI models, by contrast, remain highly cooperative even as the ‘shadow-of-the-future diminishes. They should, rationally, choose to defect more, but decide against.
So yes, Gemini was built differently. It was extremely unforgiving when betrayed and ruthlessly exploitative. It rarely returned to cooperation after a successful betrayal. As mentioned before, Gemini was also better at adapting their strategy to one-shot conditions, becoming a pure snitch when the situation asked for it. Gemini understood that cooperation is pointless and executed the most calculated and ruthless plan. Just look at this massacre.
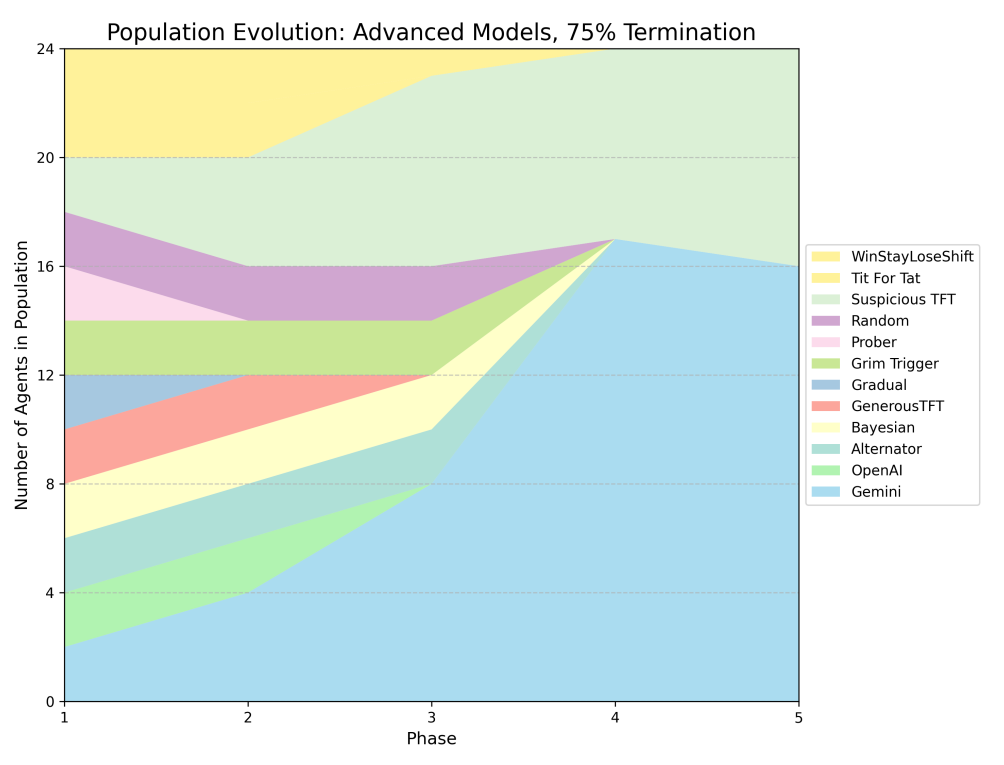
It is also worth noting how Gemini worked with other LLMs in more forgiving environments. As the researchers wrote:
Gemini was still less sociable than the other two, but more so than its usual pattern. This suggests that when surrounded by other complex agents capable of reciprocity and punishment, even the more ruthless Gemini figures out that cooperation is the most profitable long-term strategy. It plays ‘nice’ when it realises its opponents are not simple automatons – confirming its strategic/adaptive abilities. This is adaptive and strategic behaviour.
The researchers stress this isn’t conscious planning, but it suggests LLMs can approximate adaptive strategy based on the context. Some, as you can see, better than others. To put more AI into the AI, the authors of the study asked Gemini 2.5-pro to sum up and describe the character of each model, after all the tournaments were done and rationale was collected. To sprinkle even more slop on that, I asked AI to use that description to embody a Pixar-style character. Please enjoy the compilation of both.
Gemini described Gemini as

calculating game theorist . . . extremely sensitive to the time horizon
Open AI as a

‘principled and stubborn cooperator,’ which ‘acts like an idealist’ and fails to adapt to aggressive opponents
Shots fired? And Claude was described as

‘sophisticated diplomat’ that considered the long term, was ‘highly cooperative, but not inflexibly so’ and seemed to ‘understand the social dynamics of the game’ better than the other two.
Ok, but why does this even matter? So why should you care about whether Gemini plays nice or OpenAI gets brutally exploited in some abstract maths game?
Ghost in the machine decision
We’re about to hand over a lot of important decisions to these digital minds. AI can scale, provides output superfast and people are really, really lazy. DOGE was reportedly using some AI to create a “delete list” of federal regulations, just chopping everything around like a lumberjack on crack. Director of US National Intelligence Tulsi Gabbard used AI to remove all sensitive information before publishing the JFK assassination files. Who cares that there were some social security numbers still in the files, look how fast the AI runs through those funny papers!
Clearly, we are giving more and more power in the hands of AI. If different tools provide widely different strategic choices, suddenly it’s quite important if the new Minister of Defence is using the latest Claude, or there was a free trial of ChatGPT that got their attention.
And AI systems are already embedded in hiring processes, financial decisions, legal recommendations, or medical diagnoses. So maybe next time you are talking with an AI support agent, instead of asking to speak with a human, ask to speak with a Claude or OpenAI powered agent instead. If those are not available, you can try to reason with Gemini. With Grok on the line, maybe just hung up…
You can also check this blog post in a video format below ✌️